最近在开发过程中发现了一个奇怪的问题,
详情页评论区滑动到底部时,红色的MD过量滑动效果都有了
滚动条却没有显示到底,如下图
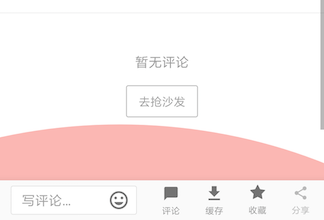
这个问题在多个业务的评论区中都有出现,虽然它们的实现略有区别
页面结构分析
正常的RecyclerView显然是不会有这样的问题的,那就得先看看我哪里用的有问题了
详情页的基本结构是一个PagingRecyclerView
(源码:https://github.com/dss886/PagingRecyclerView)
这个PagingRecyclerView的实现是在传入的Adapter外面包装了一层装饰器
在头部和底部多插入了一个header和footer用于显示下拉刷新和LoadMore的效果
@Override
public int getItemCount() {
int count = mAdapter.getItemCount();
if (mHeaderEnable) {
count++;
}
if (mFooterEnable) {
count++;
}
return count;
}
在load结束没有更多数据时会隐藏,同时高度设为0
void onHide() {
setHeight(itemView, 0);
itemView.setVisibility(View.GONE);
}
直觉告诉我,滚动条没有触底肯定跟这个Footer有关系
但是通过Layout Inspector抓到的布局显示,这个Footer确实是隐藏的,高度也为0
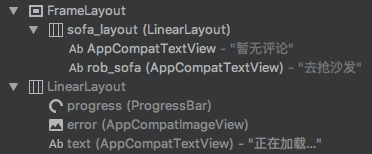
那么,问题出在哪呢?
滚动条绘制分析
ScrollBar是View的Foreground的一部分,我们先从View.draw()方法看起
View :
-> draw()
-> onDrawForeground()
-> onDrawScrollBars()
-> onDrawVerticalScrollBar()
protected void onDrawVerticalScrollBar(Canvas canvas, Drawable scrollBar,
int l, int t, int r, int b) {
scrollBar.setBounds(l, t, r, b);
scrollBar.draw(canvas);
}
可以看到,View在处理ScrollBar的时候,最终是委托给了ScrollBarDrawable这个类进行处理的
我们跟踪进ScrollBarDrawable.draw()方法看一下,打个断点
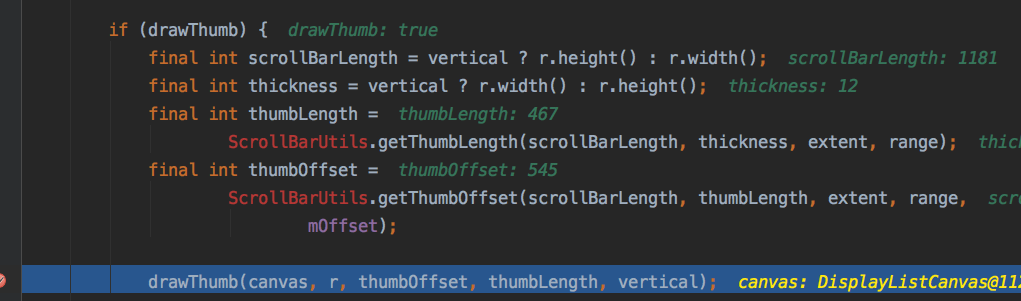
整个RecyclerView的高度(也就是scrollBarLength)是1181px,这和布局文件是一致的,
而scrollbar的显示长度(thumbLength)和起始位置(thumbOffset)分别是467px和545px,加起来还差了169px,也和现象一致
–
ScrollBarUtils的代码量很少,只有几个判断和一个除法,
从传入的range、extent、offset变量中算出实际的像素值,
这么简单的计算我不相信有问题,那么问题肯定出在传入的这几个值上了
public class ScrollBarUtils {
public static int getThumbLength(int size, int thickness, int extent, int range) {
// Avoid the tiny thumb.
final int minLength = thickness * 2;
int length = Math.round((float) size * extent / range);
if (length < minLength) {
length = minLength;
}
return length;
}
public static int getThumbOffset(int size, int thumbLength, int extent, int range, int offset) {
// Avoid the too-big thumb.
int thumbOffset = Math.round((float) (size - thumbLength) * offset / (range - extent));
if (thumbOffset > size - thumbLength) {
thumbOffset = size - thumbLength;
}
return thumbOffset;
}
}
看一下这几个值是怎么来的
if (drawVerticalScrollBar) {
scrollBar.setParameters(computeVerticalScrollRange(),
computeVerticalScrollOffset(),
computeVerticalScrollExtent(), true);
final Rect bounds = cache.mScrollBarBounds;
getVerticalScrollBarBounds(bounds, null);
onDrawVerticalScrollBar(canvas, scrollBar, bounds.left, bounds.top,
bounds.right, bounds.bottom);
if (invalidate) {
invalidate(bounds);
}
}
View的三个方法computeVerticalScrollRange/Extent/Offset返回了相应的值
- Range:代表整个可滚动View的总高度
- Extent:代表当前可视区域的实际高度
- Offset:代表当前可视区域在整个可滚动View的起始位置
而RecyclerView继承后委托了LayoutManager的相应方法来处理
我们这里用的是LinearLayoutManager,看下代码
它在找到视野内的第一个和最后一个View后,传入了ScrollbarHelper进行计算
private int computeScrollOffset(RecyclerView.State state) {
if (getChildCount() == 0) {
return 0;
}
ensureLayoutState();
return ScrollbarHelper.computeScrollOffset(state, mOrientationHelper,
findFirstVisibleChildClosestToStart(!mSmoothScrollbarEnabled, true),
findFirstVisibleChildClosestToEnd(!mSmoothScrollbarEnabled, true),
this, mSmoothScrollbarEnabled, mShouldReverseLayout);
}
我们继续跟进去看一下
Range的计算:
可见的item的高度/可见item的个数乘以整个RecyclerView的item总数,没问题
final int laidOutArea = orientation.getDecoratedEnd(endChild)
- orientation.getDecoratedStart(startChild);
final int laidOutRange = Math.abs(lm.getPosition(startChild)
- lm.getPosition(endChild))
+ 1;
// estimate a size for full list.
return (int) ((float) laidOutArea / laidOutRange * state.getItemCount());
Extend的计算:
endChild的底部 - startChild的顶部,再和totalSpace取最小值,没问题
final int extend = orientation.getDecoratedEnd(endChild)
- orientation.getDecoratedStart(startChild);
return Math.min(orientation.getTotalSpace(), extend);
Offset的计算:
用可见item的高度/可见item的个数算出平均每个item的高度,再乘以前面的item个数,也没问题
final int laidOutArea = Math.abs(orientation.getDecoratedEnd(endChild)
- orientation.getDecoratedStart(startChild));
final int itemRange = Math.abs(lm.getPosition(startChild)
- lm.getPosition(endChild)) + 1;
final float avgSizePerRow = (float) laidOutArea / itemRange;
return Math.round(itemsBefore * avgSizePerRow + (orientation.getStartAfterPadding()
- orientation.getDecoratedStart(startChild)));
这个算法是没问题的,但是从算法上来看,如果endChild取的不对
(在这个例子中,如果endChild取的是抢沙发的View,而不是隐藏的LoadMore Footer)
算出来的offset和range加起来就不等于extend,而且是刚好差了一个item的高度
(即上图中的 avgSizePerRow 值)
问题原因分析
那么,LinearLayoutManager在取endChild的时候为什么会取错呢?
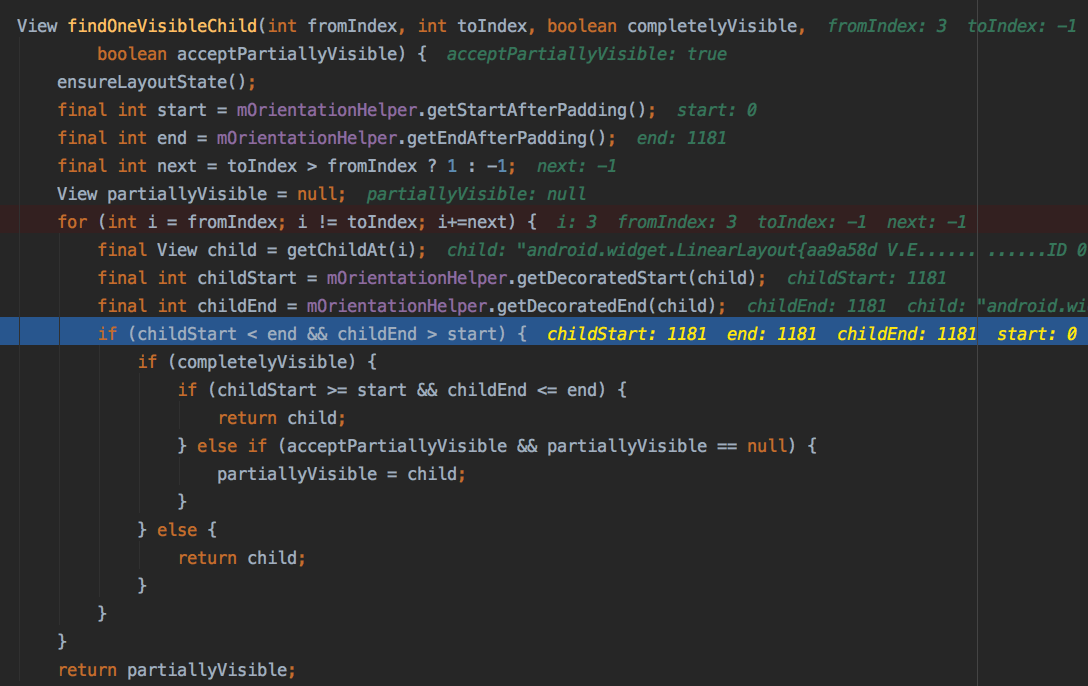
LinearLayoutManager在计算的时候最终调用的是findOneFirstVisibleChild这个方法
private int computeScrollOffset(RecyclerView.State state) {
if (getChildCount() == 0) {
return 0;
}
ensureLayoutState();
return ScrollbarHelper.computeScrollOffset(state, mOrientationHelper,
findFirstVisibleChildClosestToStart(!mSmoothScrollbarEnabled, true),
findFirstVisibleChildClosestToEnd(!mSmoothScrollbarEnabled, true),
this, mSmoothScrollbarEnabled, mShouldReverseLayout);
}
private View findFirstVisibleChildClosestToEnd(boolean completelyVisible,
boolean acceptPartiallyVisible) {
if (mShouldReverseLayout) {
return findOneVisibleChild(0, getChildCount(), completelyVisible,
acceptPartiallyVisible);
} else {
return findOneVisibleChild(getChildCount() - 1, -1, completelyVisible,
acceptPartiallyVisible);
}
}
既然是找Visible,就会取判断一下是否可见
RecyclerView的范围是0-1181,Footer的范围是1181-1181,在这里直接被跳过了,
最后命中的就是倒数第二个:抢沙发的item,最终导致了问题的出现
其它业务的评论区实现虽然不是用的PagingRecyclerView
但是在LoadMore的原理上都是一致的,都是在没有更多数据时会隐藏尾部的Item
这导致了同样的Scrollbar的位置绘制错误
解决方案
#1 治标
既然是因为高度为0的问题,那在Footer隐藏的时候高度不设为0就可以了(手动滑稽)
void onHide() {
setHeight(itemView, 1);
itemView.setVisibility(View.INVISIBLE);
}
#2 治本
高度设为1px的方案虽然能解决问题,但是太不优雅,不是我的风格
–
考虑根治这个问题的话,其实只要将FindOneVisibleChild方法的判断条件修改一下就行
但是因为这个方法用到的地方比较多,而且是package-private的,没办法直接修改
因此为保持影响范围可控,只能从几个compute方法入手,Copy一下代码去修改了
–
除了Copy的代码,还需要通过反射去取一下内部的mOrientationHelper对象
这里代码就不贴了,真正需要修改的逻辑其实只有一行:将 < 和 > 改为 <= 和 >=
for (int i = fromIndex; i != toIndex; i+=next) {
final View child = getChildAt(i);
final int childStart = mOrientationHelperCopy.getDecoratedStart(child);
final int childEnd = mOrientationHelperCopy.getDecoratedEnd(child);
// 这里将 < 和 > 改为 <= 和 >=
if (childStart <= end && childEnd >= start) {
if (completelyVisible) {
if (childStart >= start && childEnd <= end) {
return child;
} else if (acceptPartiallyVisible && partiallyVisible == null) {
partiallyVisible = child;
}
} else {
return child;
}
}
}
编译运行一下,完美,问题解决~